Navigating the Wayback Machine for Archived Web Insights
The Wayback Machine is a remarkable service that grants access to snapshots of web pages from the past. The vast landscape of the internet is teeming with data, and it’s the role of search engines to illuminate the way. While this proves invaluable when seeking information, the scenario takes a turn when attempting to expunge data, a challenge also encountered on platforms like Twitter, Instagram, Facebook and other social media networks. A common misconception among users is that once a tweet is deleted, it vanishes into oblivion. However, the reality is different. When a search engine scrutinizes your website, it captures a duplicate – a phenomenon acknowledged by Google and various search indexers as a “cached copy.”
These cached duplicates act as frozen moments in time, encapsulating websites or services in their exact state when the capture occurred. There exist additional services dedicated to caching and preserving website data for historical archives. Notably, the popularity of a site directly correlates with the likelihood of it being cached. Explore further insights into these web preservation practices and understand their impact by leveraging tools like the Wayback Machine. Uncover deleted content, track changes, and delve into the digital past with this invaluable resource
Leveraging the Wayback Machine for Web Archiving and Deleted Content Retrieval
Web archiving, facilitated through automated web crawlers, is a crucial process to gather and preserve digital information for future researchers and public reference. The Internet Archive, a non-profit platform committed to ‘universal access to all knowledge,’ plays a significant role in this endeavor. Through its digital collections, it provides users with access to a diverse range of materials, including website pages, media, and public-domain books. One standout tool offered by the Internet Archive is the Wayback Machine, allowing users to explore “snapshots” of archived pages, capturing the essence of websites at specific points in time.
The Wayback Machine becomes particularly invaluable when searching for deleted content on social media platforms like Twitter. Users can navigate the Wayback Machine’s search panel to explore Twitter profile pages and view tweets available at the time of capture. Even if a tweet was posted before the capture but deleted afterward, the Wayback Machine is likely to preserve it, offering a historical perspective not visible on the user’s current Twitter profile page. Explore the past and uncover deleted digital narratives with the power of the Wayback Machine.
Utilizing the Wayback Machine technique entails navigating through the dates when the user’s page was cached. This process enables you to uncover and scrutinize data that might have been deleted. Consider a scenario where an individual sends a potentially harmful message through social media and later decides to delete that content. However, during that interim period, there’s a possibility that the content might have been archived and securely stored for future reference. Uncover hidden digital footprints and deleted content by leveraging the capabilities of the Wayback Machine.
How does archive.org work?
The Wayback Machine is a remarkable service that grants access to snapshots of web pages from the past. To explore an earlier version of a website, simply input the page’s URL on the Wayback Machine website. Subsequently, a list of saved snapshots of the webpage from different points in time will be displayed. You can choose a specific snapshot to witness how the webpage looked during that particular moment.
Utilizing a process known as “web crawling,” the Wayback Machine collects and stores copies of websites. Web crawling is an automated procedure where specialized software, often referred to as a “crawler” or “spider,” traverses the web, visiting various websites. The software then stores a copy of the webpage in the Wayback Machine’s database.
The Wayback Machine is an initiative by the Internet Archive, a nonprofit organization dedicated to building a digital library of websites and other cultural artifacts. Additional projects include Open Library and archive-it.org. Embark on a journey through time with the Wayback Machine, unraveling the history of digital landscapes.
Using Wayback tool
Do you remember what twitter was like when it started? With wayback machine we will go back in time and see how one of the largest and most influential social networks in the world has progressed.
First we will search for the page in question in the Wayback machine tool. Once we perform the search we see 2,147,116 snapshots performed for that domain.
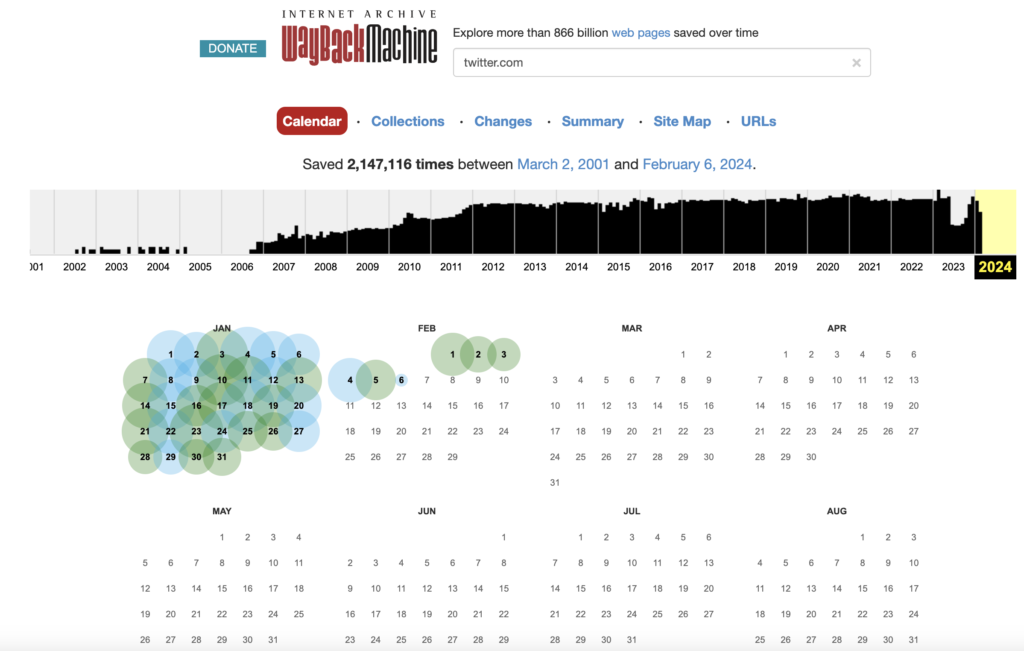
Once all the snapshots are displayed, we will review two at random.
- The first one will be taken from November 18, 2006.
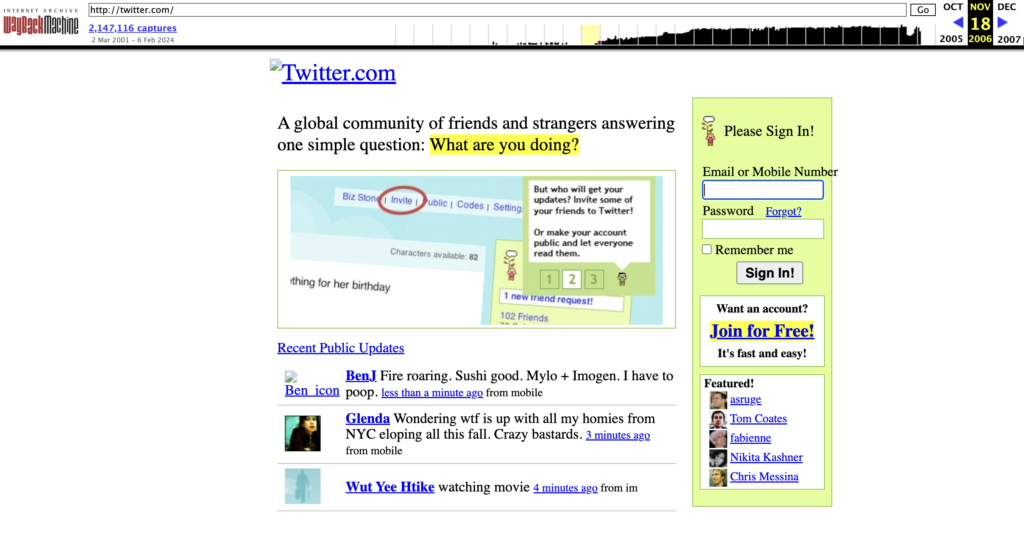
- The second one will be taken from February 05, 2011.

As we have seen, being able to see cached websites as they were before is something that can be done easily. The important thing about this tool is that we can use it to search for deleted content.

